
What is Kafka? What is it used for?
Nowadays, event-driven architecture is very popular in the design of distributed systems. Kafka, developed by Apache, provides an open-source software for this purpose, with its streaming-based service for message transmission/publication. Technically, Kafka provides a means to enable a continuous flow of data. It is widely used and has been adopted by many large companies. Here is a – non-exhaustive – list of some prominent Kafka features:
- easy connection/integration,
- scalability,
- it’s fault-tolerant and provides high availability
- large number of client distributions,
- command line toolset for administrative tasks,
- large community support,
- high-level documentation.
A short presentation: https://kafka.apache.org/intro
Kafka topics
Kafka uses so-called topics to keep the messages flowing. Each topic has one or more writer/publisher page (we call them producers) and one or more reader/processor page (we call them consumers). The publisher simply posts their message to the topic, and the reader reads it and commits it to the topic, saying that they have processed it from the event stream.
Each topic forms a logical unit, which Kafka divides into several partitions (i.e. the smallest storage unit) among the brokers (i.e. servers available in the cluster). This has several advantages:
- replicates data: it can maintain multiple copies of partitions on different servers at the same time,
- so this way the data will not be found on just one server,
- consumer copies can read from various brokers in parallel
Processing messages
Consumers process messages at group level. Each consumer group subscribes to the topic with a unique id, called the consumer group id (which is used to publish which processing group it belongs to). A group can spawn several consumers at the same time (easily scaled up e.g. in case of increased messages, but vice versa, easily scaled down when normal operation is restored), which serve the same purpose: read the message and process it. If multiple instances have been started with the same group id then it is irrelevant for processing purposes which processor picked up the message. In the case where several consumer groups have subscribed to the topic, the id becomes important, because until all consumer groups confirm that they have processed the message, it must be kept (retention time: this value can be set globally with the Kafka server configuration but can also be defined topic by topic). Attention must be paid that consumer groups do not use each other’s ids, because a situation could occur where they snatch messages from each other.
The example below represents two groups of writers and one group of readers (starting with 2 instances).
What can we automate?
It is worth automating routine tasks which need to be done regularly. This is beneficial for several reasons:
- time and input costs may be reduced,
- no need to do the same task more than once,
- a possible mistake can be avoided,
- focus is on the business need,
- reduce the amount of administration,
- possible to generate inputs and outputs (e.g. audit log)
In a large corporate environment, lead time usually involves several rounds of approval, only after that can implementation begin. If it is not the same team responsible for both processes, it can take even longer. In an automated process, these steps can be completed much more quickly, as execution is ideally a matter of pressing one button.
Creating a Kafka topic or setting permissions on it are routine tasks. It makes no difference when executing on topic A or B: it can be well described, it can be done by issuing declarative commands one after the other, in short it is “scriptable”. What does it mean in practice? It means one or more execution jobs that can be easily inserted into a project CI/CD pipeline.
Ansible playbook vs. command line tools
An obvious solution for that would be to write an Ansible playbook which helps to perform declarative tasks. It is important not to create something that already exists and has available support. Ansible scripts cannot be used to perform operational DevOps tasks in a Kafka environment. On the other hand, it provides very good support in building a Kafka cluster.
Apache has released a quickstart kit (in the form of sh scripts) with which we can perform operational DevOps processes. These scripts were used to create the job in the sample project, which can create a topic and set permissions on it.
The kit is available here: https://kafka.apache.org/quickstart
Bitbucket
When designing an automated process, we need to define conventions that can be clearly built upon in the processes, such as the naming of a topic or the naming of administrative files.
Bitbucket as a version manager can be used for administration. In the sample project, each Kafka topic has its own repository. When a new topic is created, a new repository has to be created, the first step being to decide on the name. In order to do this, we define the following convention: topic-name (separated by hyphens if it consists of several words).
Each repository will contain the number of descriptors corresponding to the environments it will run. This is necessary because, in general, they will be created with different configurations and different users will write/read topics in different environments. In the example we will create a number of descriptors corresponding to DEV, UAT and PROD environments. Based on the environment identifier (topic_name + “_environment”), the following files have been created by postfix for the “notifications” topic:
| Environment | Example file name |
| DEV | notifications_dev.yaml |
| UAT | notifications_uat.yaml |
| PROD | notifications_prod.yaml |
Scheme definition
Each topic communicates their target state in a uniform format. The files describe the current state of the environment they refer to. With change management, it is easy to trace back what settings/permissions a topic contained in a particular version. The schema defines what data is required to enforce the appropriate Kafka scripts. The name, replication, partition section contains the information needed to create the topic, the acl (access control lists) section contains the permission settings.
name: notifications_dev
replication: ‘2’
partition: ‘4’
acl:
– principal: _proj_microservice_dev
consumerGroup: dsp_microservice_read_dev
role: consumer
– principal: _proj_microservice-2_dev
role: producer
– principal: _proj_microservice-3_dev
consumerGroup: dsp_microservice-3_read_dev
role: consumer
– principal: _proj_microservice-4_dev
role: producer
Here we can specify further restrictions in the naming of principals and, for consumers, in the consumerGroup identifiers (the example above uses the _proj prefix). This is important because the script or even the review process can catch unconventionally created identifiers.
In the fortunate situation where the identifiers differ only in the environment identifier, parameters can be used. In this case there is no need for 3 files, it can simply be written this way:
name: notifications_${ENV_NAME}
replication: ‘2’
partition: ‘4’
acl:
– principal: _proj_microservice_${ENV_NAME}
consumerGroup: dsp_microservice_read_${ENV_NAME}
role: consumer
– principal: _proj_microservice-2_${ENV_NAME}
role: producer
– principal: _proj_microservice-3_${ENV_NAME}
consumerGroup: dsp_microservice-3_read_${ENV_NAME}
role: consumer
– principal: _proj_microservice-4_${ENV_NAME}
role: producer
(The parameter is given to the executing job at startup.)
Branching strategy
The branching strategy in use applies to all repositories.
| branch | description | comment |
| master | Describes the current state. | Protected branch. Code can only be delivered via Pull request. A release can be issued , from this branch, also a release tag will be automatically added during the merge. |
| feature/task-id | The feature branches contain the changes related to the ongoing development. Their life cycle lasts until the development team makes the necessary changes and submits them as a new pull request to the master branch. | With this branch you can test (even with a dry-run job) the changes you have made. During development, errors will be detected (e.g. incorrect topic name or missing consumerGroup identifier for consumer). |
(A release branch is not needed, you can release from the master state, or bugfix by tags.)
Privilege settings
For a change to reach the “production” stage, it needs proper quality assurance. This can be ensured by creating endorser group(s) and rules in a Bitbucket environment, which can be set up by the admins.
By involving the right members, we have set up the following groups:
| Bitbucket endorser group | kafka-merge | Eligibility for endorsement. This circle only includes members who are responsible for the operation of Kafka on the project. |
| Bitbucket editor group | kafka-editor | Developer group, writing privileges (except master branch). |
| Bitbucket reader group | kafka-read | Reading privileges (cannot push code on the branch). |
(It might happen that several groups must have control over the acceptance of a new claim and at least one endorsement per group is required.)
CI/CD process
For the installation, the Kafka descriptor files can be released as an artifact e.g. in Nexus or used as a master branch with the appropriate tag. The steps of the process in chronological order:
| Pull request | In short, by submitting PR, you create a request to change the environment (also to create a topic). PR provides the control, to ensure that only changes that have passed the endorsement process are committed to the master branch. |
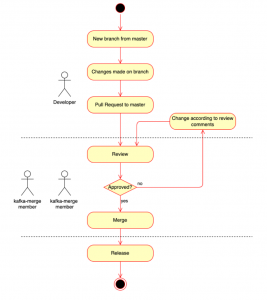
| Merge | The PR is approved by the default reviewers (ie. members of the kafka-merge group). |
| Release | Create release artifact from the master branch (optional if the tag is acceptable). |
| Setup | Job runs the script in the appropriate environment (DEV, UAT, PROD). |
Pull request/review
The development team submits a change request (including topic creation) to the master branch within PR, and the default reviewers (members of the kafka-merge group) are automatically notified.
How do jobs work?
The files registered in Bitbucket describe current Kafka states with privileges, environment parameters, etc. The files can be used as input to an automated process that creates (including topics) and/or assigns the appropriate privileges in the environment using the appropriate Kafka command line tools.
Prerequisites:
- The CI/CD platform, that controls the running of the job. The example executes instructions through a Jenkins job.
- A Kafka technical user, who — with the appropriate privileges — can run the commands in the job. It is important to note here that the technical user needs a high-level privilege, so the review is very important in ensuring that only changes that have been previously approved (from both a business and technical point of view) are introduced into the system.
The flowchart below represents the execution (synced) steps:
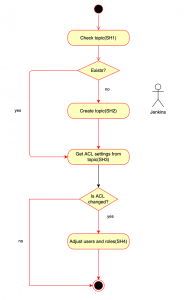
Querying Kafka topics (SH1)
The first step in the process is to be able to query whether or not the given Kafka topic exists in the appropriate environment. In order to do this, the following command line tool can be used, where the only parameter is the zookeeper host (a variable that rarely or never changes, so it is defined as a static variable in the code):
| kafka-topics.sh –zookeeper zk01.example.com:2181 –list |
Creating a Kafka topic (SH2)
To create a Kafka topic, run the following command line tool. The parameters are compatible with the keys under the metadata in the yaml file defined for the environment.
| kafka-topics.sh –create –zookeeper {$zookeeper}
–topic {$topic} –partitions {$num_of_partitions} –replication-factor {$num_of_replication_factor} |
| parameters | description | source |
| zookeeper | Zookeper host address. | From a pre-defined static variable. |
| topic | Name of the topic to be created. | Definite name property in YAML. |
| num_of_partitions | Number of partitions, how many physical partitions the topic will be divided into. Important: it can only be changed to a higher number later without losing data.
Calculation may be required in the design phase to achieve the correct throughput: https://dattell.com/data-architecture-blog/kafka-optimization-how-many-partitions-are-needed/ |
Number of partitions, how many physical partitions the topic will be divided into. Important: it can only be changed to a higher number later without losing data. Calculation may be required in the design phase to achieve the correct throughput: https://dattell.com/data-architecture-blog/kafka-optimization-how-many-partitions-are-needed/ Definite partition property in YAML. |
| num_of_replication_factor | Determines the number of replications: how many Kafka brokers the data should be replicated on. | Definite replication property in YAML. |
ACL query on a Kafka topic (SH3)
The current permission settings for a given topic can be queried by running the following command line tool:
| kafka-acls.sh –authorizer-properties zookeeper.connect={$zookeeper} –list |
After processing the result, the Jenkins job is able to decide whether further adjustment of the topic is necessary.
Setting privileges on a Kafka topic (SH4)
For setting privileges on a Kafka topic, you can use the following command line tools. 2 types of privileges can be set:
| privilege | type | cli |
| consumer | Reader privilege. | kafka-acls.sh –authorizer-properties zookeeper.connect={$zookeeper} –add –consumer –allow-principal User:{$user} –topic {$topic} –group {$group_id} |
| producer | Writer privilege. | kafka-acls.sh –authorizer-properties zookeeper.connect={$zookeeper} –add –producer –allow-principal User:{$user} –topic {$topic} |
| parameter | description | source |
| zookeeper | Zookeper host url. | From a pre-defined static variable. |
| user | user Name of the consumer/producer. |
Definite principal property in YAML. |
| group_id | In the case of consumers, it is mandatory to specify a consumer group id to identify the processing group. |
Conclusion
In a microservices architecture, a Kafka cluster can play a central role in the infrastructure. As an effect, the administration of new or existing Kafka topics becomes a regular task. During the refinement of releases, many environment request problems can be avoided if a similar solution is part of the CI/CD pipeline, thus ensuring the stable operation of our application.




